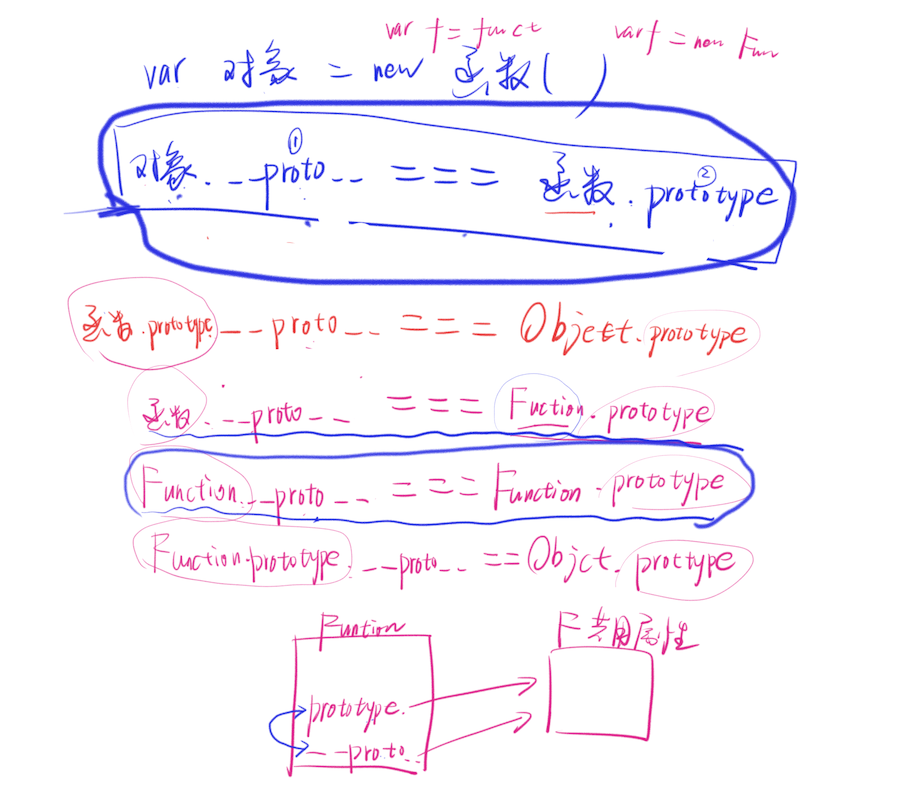
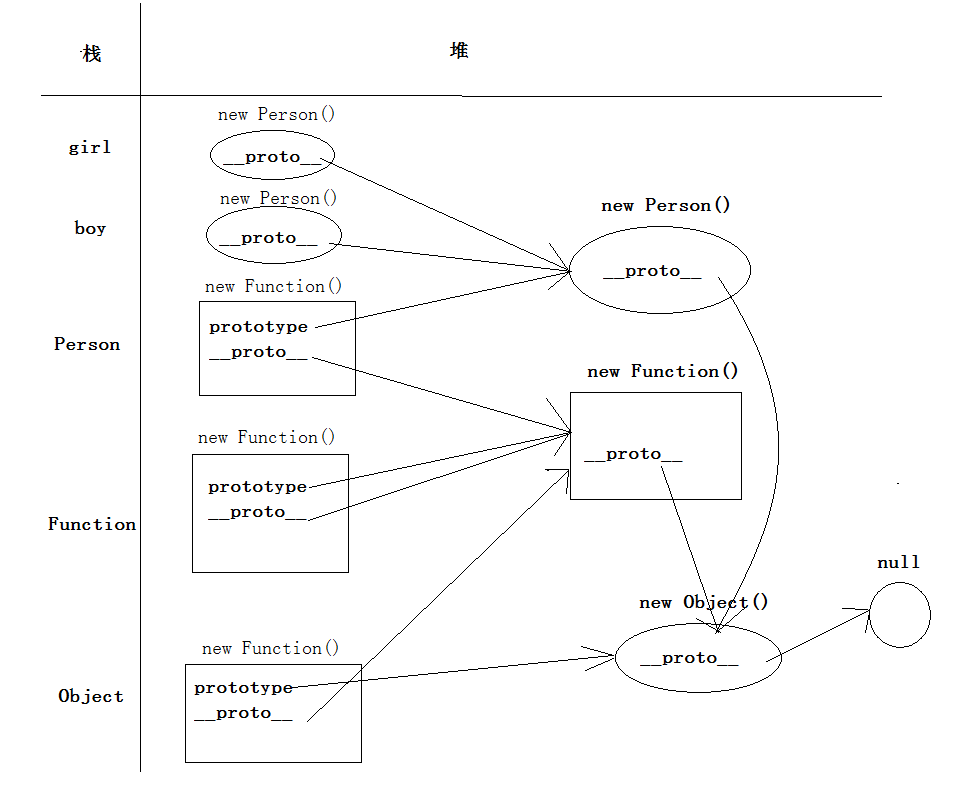
基本概念
分布式系统是一个古老而宽泛的话题,近年因“大数据”等概念的兴起,又焕发出了青春。
总的来说,分布式系统要做的任务就是把多台机器有机的组合,连接起来,让其协同完成同一件任务,可以是计算任务,也可以是存储任务。
分布式系统大概包括三大部分:
- 分布式存储系统
- 分布式计算系统
- 分布式管理系统
分布式存储系统
分布式存储系统大概可以分为四个子方向:
- 结构化存储
- 非结构化存储
- 半结构化存储
- In-memory 存储
结构化存储(structured storage systems)
典型场景就是 事务处理系统或关系型数据库。 结构化存储系统强调的是:
- 结构化的数据(例如关系表)。
- 强一致性(例如银行系统,电商系统等场景)。
- 随机访问(索引,增删改查,SQL语言)。
然而,正是由于这些性质和限制,结构化存储系统的可扩展性通常不是很好,这在一定程度上限制了大数据环境下的表现。
非结构化存储(no-structured storage systems)
和结构化存储不同,非结构化存储强调的是高扩展性,典型的系统就是分布式系统。
Google在2013年推出的GFS(google file system)做出了里程碑的一步,其开源实现对应为HDFS.GFS的主要思想包括:
- 用master来管理metadata。
- 文件使用64MB的chunks来存储,并且在多个server上保存多个副本。
- 自动容错,自动错误恢复。
虽然分布式文件系统的可扩展性,吞吐率都非常好,但几乎无法支持随机访问(random access)操作,通常只能进行文件追加(append)操作。 这使得非结构化存储系统很难面对低延时,实时性较强的应用。
半结构化存储(semi-structure storage systems)
半结构化存储便是为了解决结非构化存储系统随机访问性能差的问题。NoSQL,Key-Value Store,对象存储等都属于半结构化存储研究的领域。 NoSQL系统既有分布式文件系统所具有的可扩展性,又有结构化存储系统的随机访问能力(例如随机update, read 操作),系统在设计时通常选择简单键值(K-V)进行存储,抛弃了传统RDBMS里复杂SQL查询以及ACID事务。这样做可以换取系统最大的限度的可扩展性和灵活性。
In-memory存储
随着业务的并发越来越高,存储系统对低延迟的要求也越来越高。In-memory存储顾名思义就是将数据存储在内存中, 从而获得读写的高性能。比较有名的系统包括memcahed,以及Redis。这些基于K-V键值系统的主要目的是为基于磁盘的存储系统做cache。
NewSQL
在结构化存储中提到,单机RDBMS系统在可扩展性上面临着巨大的挑战,然而NoSQL不能很好的支持关系模型。那是不是有一种系统能兼备RDBMS的特性(例如:完整的SQL支持,ACID事务支持),又能像NoSQL系统那样具有强大的可扩展能力呢?
2012年Google在OSDI上发表的Spanner,以及2013年在SIGMOD发表的F1,让业界第一次看到了关系模型和NoSQL在超大规模数据中心上融合的可能性。 不过由于这些系统都太过于黑科技了,没有大公司支持应该是做不出来的。比如Spanner里用了原子钟这样的黑科技来解决时钟同步问题,打破光速传输的限制。在这里只能对google表示膜拜。
分布式计算系统
分布式计算最为核心的部分就是容错。由于硬件的老化,有可能会导致某台存储设备没有启动起来,某台机器的网卡坏了,甚至于计算运行过程中断电了,这些都是有可能的。然而最平凡发生的错误是计算进程被杀掉。
分布式计算系统大概分为如下几类:
- 传统基于msg的系统
- MapReduce-like系统
- 图计算系统
- 基于状态(state)的系统
- Streaming系统
传统基于msg的系统
这类系统里比较有代表性的就是 MPI(message passing interface)。MPI除了提供消息传递接口之外,其框架还实现了资源管理和分配,以及调度的功能。除此之外,MPI在高性能计算里也被广泛使用,通常可以和Infiniband这样的高速网络无缝结合。
除了send和recv接口之外,MPI中另一个接口也值得注意,那就是AllReduce。使用AllReduce通常只需要在单机核心源码里加入AllReduce一行代码,就能完成并行化的功能。因为其底层消息传递使用了tree aggregation,尽可能的将计算分摊到每一个节点。
因为MPI不支持容错,所以很难扩展到大规模集群之上。
MapReduce-like系统
这一类系统又叫作dataflow系统,其中以MapReduce(Hadoop)和Spark为代表。这一类系统的特点是将计算抽象成为high-level operator,例如像map,reduce,filter这样的函数式算子,然后将算子组合成DAG,然后由后端的调度引擎进行并行化调度。
MapReduce-like的编程风格和MPI截然相反。MapReduce对程序的结构有严格的约束——计算过程必须能在两个函数中描述:map和reduce;输入和输出数据都必须是一个一个的records;任务之间不能通信,整个计算过程中唯一的通信机会是map phase和reduce phase之间的shuffling phase,这是在框架控制下的,而不是应用代码控制的。因为有了严格的控制,系统框架在任何时候出错都可以从上一个状态恢复。
由于良好的扩展性,许多人都机器学习算法的并行化任务放在了这些平台之上。然而这些系统最大缺点有两点:
- 这些系统所能支持的机器学习模型通常都不是很大。导致这个问题的主要原因是这系统在push back机器学习模型时都是粗粒度的把整个模型进行回传,导致了网络通信的瓶颈。
- 严格的BSP同步计算使得集群的效率变的很低。也就是说系统很容易受到straggle的影响。
图计算系统
图计算系统是分布式计算里另一个分支,这些系统都是把计算过程抽象成图,然后在不同节点分布式执行,例如PageRank这样的任务,很适合用图计算系统来表示。
最早成名的图计算系统当属Google的pregel,该系统采用BSP模型,计算以vectex为中心。 除了同步(BSP)图计算系统之外,异步图计算系统里的佼佼者当属GraphLab,该系统提出了GAS的编程模型。
基于状态(state)的系统
这一类系统主要包括2010年OSDI上推出的Piccolo,以及后来2012年nips上Google推出的dist belief再到后来被机器系学习领域广泛应用的Parameter Server架构。
ParameterServer这种state-centric模型则把机器学习的模型存储参数上升为主要组件,并且采用异步机制提升处理能力。它通过采用分布式的 memcached 作为存放参数的存储,这样就提供了有效的机制作用于不同worker节点同步模型参数。
Streaming 系统
Streaming系统是为流式数据提供服务的。其中比较有名的系统包括Storm,SparkStreaming,Flink等等。
分布式管理系统
暂无笔记。
学习总结
鉴于新冠肺炎疫情封城措施,在磊哥的建议下初识了分布式的广阔世界。希望以后有机会能根据公司的业务场景,去继续深挖学习其中一个方向,并在实战中做出成果。